
Apache Spark sert à faire du traitement de données massif : batch, streaming, SQL, machine learning, graphes.
Société : Apache Software Foundation
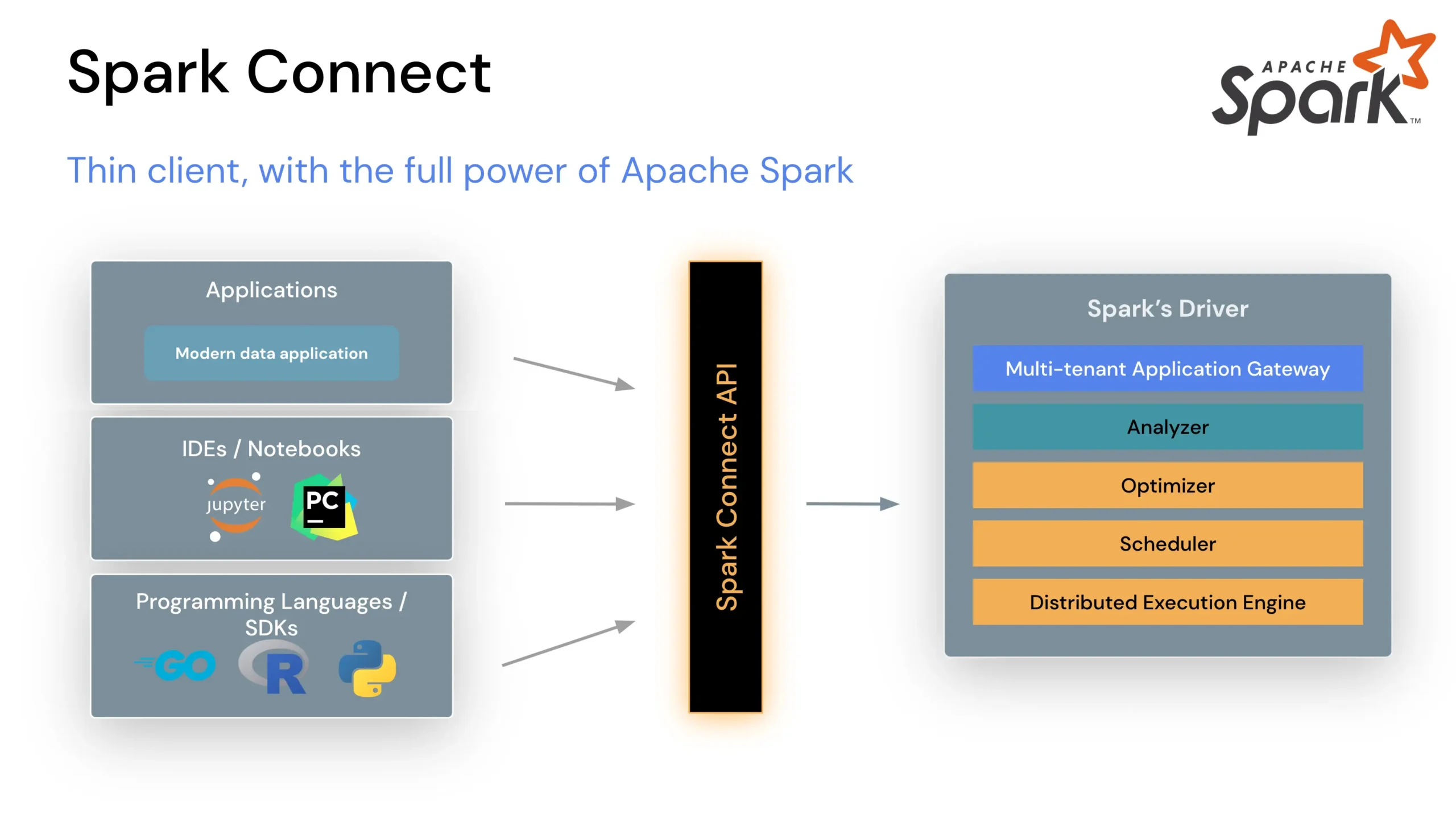
Apache Spark est un moteur d’analyse distribué conçu pour exécuter des traitements data à grande échelle, sur une machine seule ou sur un cluster. Il supporte plusieurs langages : Python, SQL, Scala, Java et R. Son intérêt : permettre aux équipes data de traiter, transformer, agréger et analyser de très gros volumes de données plus vite qu’avec des architectures historiques type MapReduce.
Spark couvre plusieurs usages :
ETL / ELT : nettoyage, transformation et préparation de données.
Data engineering : pipelines batch ou streaming.
Analyse SQL avec Spark SQL.
Machine learning avec MLlib.
Streaming avec Structured Streaming.
Traitement distribué sur cluster, Kubernetes, cloud ou infrastructure interne.
C’est un outil solide, puissant, mais pas magique. Spark devient pertinent quand les volumes, la complexité ou les temps de traitement justifient une architecture distribuée. Pour traiter trois CSV de 20 Mo, c’est souvent un marteau-pilon pour écraser une mouche.
Apache Spark est maintenu par l’Apache Software Foundation. Le site officiel le présente comme un moteur multi-langage pour la data engineering, la data science et le machine learning, utilisable sur machine unique ou cluster. La documentation officielle précise qu’il inclut Spark SQL, pandas API on Spark, MLlib, GraphX et Structured Streaming.

Discutons de vos besoins !
- Pouvez-vous piloter votre activité avec des données vraiment fiables ?
- Pouvez-vous piloter votre activité avec des données vraiment fiables ?
- Avez-vous une vision unifiée entre vos données marketing, commerciales et opérationnelles ?
- Cherchez-vous à industrialiser la production de contenus et de documents métier grâce à l’IA ?
- Vos équipes passent-elles trop de temps sur des tâches manuelles qui pourraient être automatisées ?

Nos agences expertes





Outils similaires

BigQuery

Apps Script

Google Sheets

Google Workspace

Google Dataform

Streamlit

DBT

Apache Airflow
