
Observabilité de l’IA : Surveiller efficacement les systèmes IA
Un chatbot qui répond faux.
Un agent IA métier qui dérive.
Un workflow intelligent qui consomme 3 000 € de tokens en un week-end.
Ce n’est pas un bug. C’est l’absence de garde-fous et de monitoring.
Besoin d'aide ? Découvrez les solutions de notre agence IA.
Le monitoring des LLM permet de suivre la performance, les coûts, la qualité et les dérives potentielles d’un modèle de langage en production.
Sans ça, vous avez un prototype. Pas un système industriel.
Notre agence IA considère le tracking et l’observabilité IA comme une brique stratégique, au même titre que le tracking Analytics ou la centralisation dans BigQuery. Une IA non monitorée, c’est une décision métier sans tableau de bord.
- Observabilité de l'IA : Surveiller efficacement les systèmes IA
- 1. Fondements du monitoring de LLM
- 2. Les piliers de la surveillance d’un modèle de langage
- 3. Métriques clés et KPIs
- 4. Mettre en place un système de monitoring efficace
- 5.1 Détection des hallucinations et biais
- 5.2 Stratégies de remédiation
- 6. Monitoring et LLMOps
- 7. Les leaders du monitoring LLM
- 8. Stacks d’Observabilité IA selon le type d’entreprise
- 9. Architecture hybride recommandée (quel que soit le profil)
- 10. Gouvernance, RGPD et AI Act
- Contacter un expert IA
1. Fondements du monitoring de LLM
1.1 Définition et périmètre de l’observabilité LLM
Le monitoring LLM consiste à collecter, tracer et analyser :
- Les prompts utilisateurs
- Les réponses générées
- Les tokens consommés
- La latence
- Les erreurs
- Les signaux de qualité (pertinence, hallucination, toxicité, biais)
Contrairement au monitoring classique (CPU, RAM, uptime), ici on surveille aussi le comportement sémantique.
On parle alors d’observabilité LLM :
Logs + Métriques + Traces + Évaluation sémantique.
Dans une architecture RAG (LLM + base vectorielle), on trace :
- Prompt utilisateur
- Requêtes embeddings
- Documents récupérés
- Appels API LLM
- Réponse finale
- Post-traitement éventuel
Sans traçabilité de bout en bout, impossible de comprendre pourquoi l’agent répond mal.
1.2 Les objectifs stratégiques : au-delà de la surveillance technique
Le monitoring LLM n’est pas un gadget de DevOps assoiffé de compléxité technologique.
Il sert à :
- Garantir l’alignement métier
- Maîtriser les risques (RGPD, AI Act, biais, hallucinations)
- Optimiser les coûts
- Piloter le ROI
- Protéger la réputation
Une IA non monitorée est juridiquement fragile.
Et financièrement imprévisible.
2. Les piliers de la surveillance d’un modèle de langage
2.1 Performance opérationnelle et efficacité des ressources
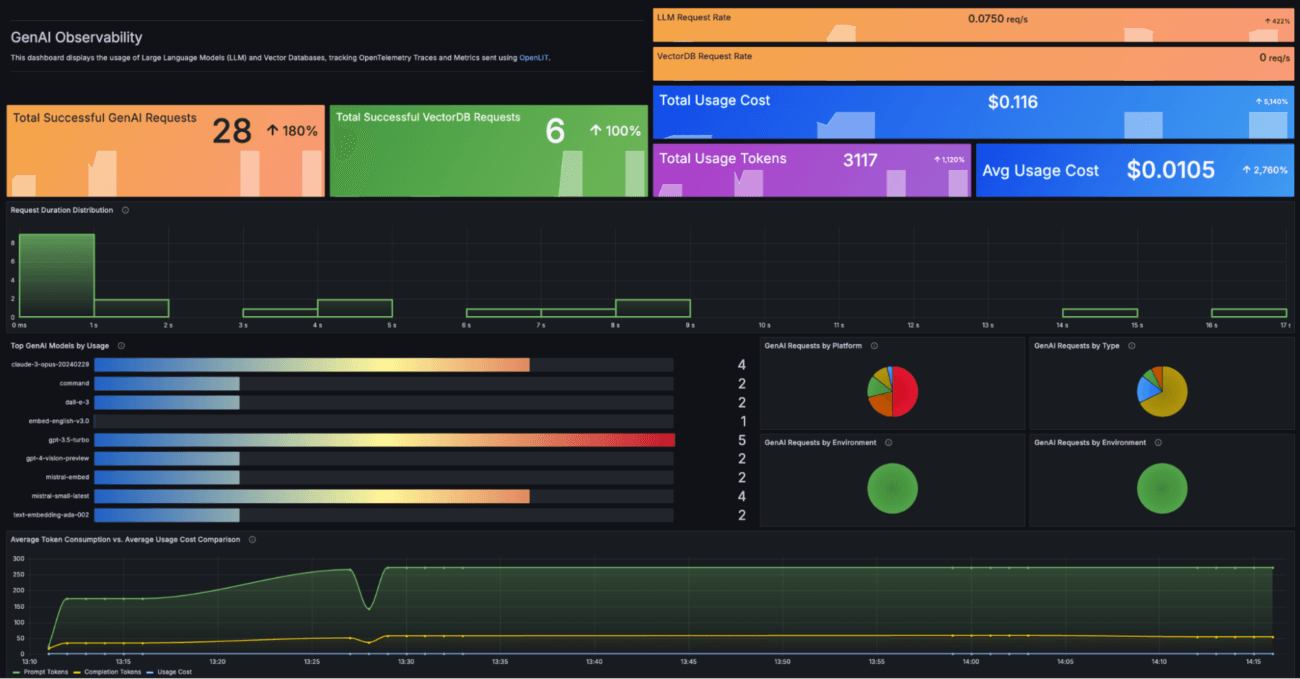
On commence par le socle technique :
- Latence (P95 / P99)
- Throughput (RPS)
- Taux d’erreur
- Disponibilité
- Consommation CPU/GPU
- Débit réseau
Exemple KPI :
| KPI | Objectif | Seuil critique |
|---|---|---|
| Latence P95 | < 2s | > 5s |
| Taux erreur API | < 1% | > 3% |
| Disponibilité | 99,9% | < 99% |
Une IA lente est perçue comme incompétente.
L’utilisateur n’analyse pas la stack technique. Il part.
2.2 Qualité de la réponse et pertinence métier
C’est ici que le monitoring devient sérieux.
Dimensions critiques :
| Dimension | Métrique possible |
|---|---|
| Pertinence | Similarité sémantique (cosine similarity) |
| Hallucination | Taux de factualité validée |
| Biais | Score d’équité |
| Toxicité | Score modération |
| Respect du format | Validation JSON / Regex |
On peut utiliser un LLM-as-a-Judge pour évaluer les réponses.
Sans métrique qualité, on pilote à l’intuition.
L’intuition en IA coûte cher.
3. Métriques clés et KPIs
3.1 Latence, débit, taux d’erreur
KPIs fondamentaux :
- End-to-End Latency
- Temps génération LLM
- Temps récupération RAG
- Erreurs parsing
- Erreurs timeout
Dans une architecture agentique (Make, n8n, orchestrateurs custom), on doit tracer chaque étape.
Sinon, impossible d’identifier le goulot.
3.2 Coût LLM et utilisation des tokens
Les fournisseurs facturent au token.
Formule standard :
Coût = (tokens entrée × prix entrée) + (tokens sortie × prix sortie)
Indicateurs à suivre :
| Indicateur | Pourquoi |
|---|---|
| Coût par requête | ROI unitaire |
| Coût par session | Impact utilisateur |
| Ratio output/input | Verbosité excessive |
| Coût par fonctionnalité | Arbitrage produit |
Exemple concret :
Un chatbot interne RH mal optimisé peut multiplier par 3 son coût mensuel simplement à cause de prompts trop longs.
Le prompt engineering est un levier financier.
4. Mettre en place un système de monitoring efficace
4.1 Étapes du déploiement
- Instrumentation (callbacks, logs structurés)
- Centralisation (Data Warehouse : BigQuery, Snowflake)
- Enrichissement contextuel
- Calcul des KPIs
- Dashboard (Looker Studio, Grafana)
- Alerting (Slack, email, webhook)
Dans notre agence, nous centralisons souvent les logs LLM dans BigQuery pour permettre :
- Analyse avancée SQL
- Détection anomalies
- Croisement CRM / usage IA
- Analyse ROI par segment
Une IA sans data warehouse est une IA aveugle.
4.2 Architecture technique
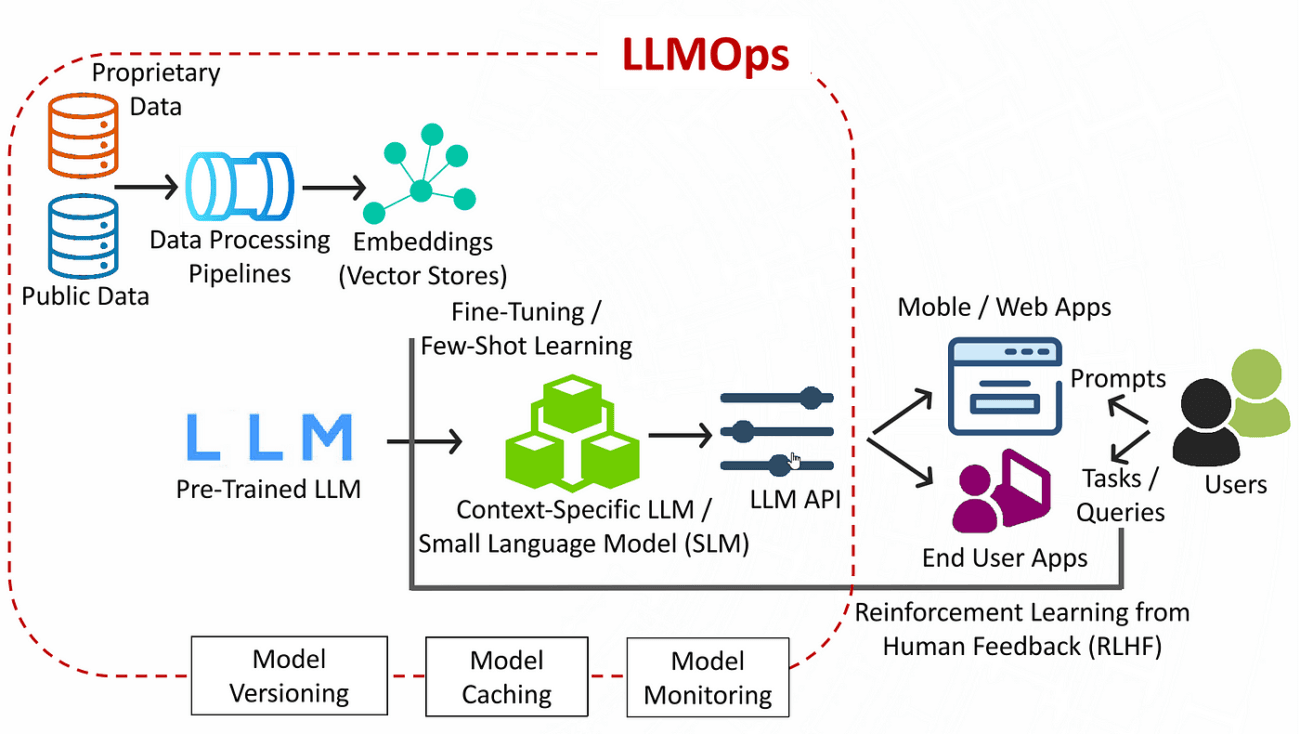
Stack typique :
- Instrumentation : OpenTelemetry
- Framework : LangChain / LlamaIndex
- Stockage métriques : Prometheus
- Logs : ELK
- Dashboard : Grafana
- Data : BigQuery / Snowflake
- Alerting : OpsGenie / Slack / Email
5. Identifier et gérer la dérive du modèle
5.1 Détection des hallucinations et biais
Types de dérive :
- Drift sémantique
- Drift comportemental
- Drift instructionnel
- Drift contextuel
Méthodes :
- Échantillonnage humain
- LLM-as-a-judge
- Comparaison embeddings
- Test dataset de référence
Des recherches sur arXiv montrent que les embeddings LLM détectent efficacement les dérives distributionnelles.
5.2 Stratégies de remédiation
- Prompt engineering
- Guardrails
- Validation sortie JSON
- Filtrage post-traitement
- Fine-tuning
- Changement modèle
Le monitoring déclenche l’action.
Sans mesure, pas de correction.
6. Monitoring et LLMOps
Le monitoring doit couvrir :
- Dev
- Test
- Prod
- Optimisation continue
Inspiré des pratiques DevOps et du cadre AI Risk Management Framework du National Institute of Standards and Technology, l’objectif est :
- Auditabilité
- Traçabilité
- Gestion des incidents
- Conformité réglementaire
7. Les leaders du monitoring LLM
| Outil | Spécificité | Année création | + | − | Prix moyen | Nb clients (estimé) | URL |
|---|---|---|---|---|---|---|---|
| LangSmith (LangChain) | Observabilité native pour apps LLM, tracing RAG, évaluation prompts | 2023 | Intégration profonde LangChain, UX développeur, évaluation comparative | Moins adapté hors écosystème LangChain | ~39–99$/mois dev, Enterprise sur devis | >100 000 devs utilisent LangChain (écosystème) | https://smith.langchain.com |
| Arize AI | Observabilité ML + LLM enterprise | 2020 | Détection drift avancée, biais, monitoring production robuste | Complexe pour PME | Enterprise (souvent >20k$/an) | 100+ entreprises (Uber, Spotify…) | https://arize.com |
| Weights & Biases (W&B) | Tracking expérimentation ML/LLM | 2017 | Standard recherche IA, versioning, tracking fin | Moins orienté monitoring temps réel business | Gratuit (limited) / Team ~50$/utilisateur/mois | >1000 organisations, 500k+ utilisateurs | https://wandb.ai |
| Datadog (LLM Observability) | Monitoring infra + LLM intégré | 2010 | Stack unifiée infra + app + LLM | Coût élevé à l’échelle | ~15–30$/host/mois + modules | 25 000+ clients | https://www.datadoghq.com |
| Grafana (Grafana Labs) | Observabilité open source flexible | 2014 | Open source, personnalisable, puissant | Nécessite intégration technique | Gratuit OSS / Cloud payant | 10M+ utilisateurs OSS | https://grafana.com |
| Helicone | Open-source LLM monitoring, proxy API | 2023 | Simple, rapide à intégrer, centré tokens/coûts | Moins complet sur qualité sémantique | Gratuit / Pro ~20$/mois | Plusieurs milliers d’utilisateurs | https://www.helicone.ai |
| WhyLabs (WhyLabs + LangKit) | Monitoring dérive & qualité LLM | 2019 | Focus dérive, data quality, éthique | Positionnement plus data science | Enterprise | 100+ entreprises | https://whylabs.ai |
| OpenAI Usage Dashboard | Monitoring natif API OpenAI | 2015 | Intégré, simple, tokens + coûts | Limité à métriques basiques | Inclus API | Millions développeurs | https://platform.openai.com |
8. Stacks d’Observabilité IA selon le type d’entreprise
| Profil entreprise | Volume IA estimé | Objectif principal | Instrumentation | Monitoring / Outil principal | Data Warehouse | Dashboard | Alerting | Complexité | Quand le recommander |
|---|---|---|---|---|---|---|---|---|---|
| Startup / PME | < 200k requêtes/mois | Contrôle coûts & stabilité | Proxy LLM (Helicone), logs backend | Helicone / Usage API natif | BigQuery | Looker Studio | Slack / Email | Faible | 1–3 chatbots, usage modéré, besoin ROI rapide |
| PME structurée | 200k–500k requêtes/mois | Maîtrise qualité & coûts | OpenTelemetry + logs structurés | Helicone + scoring custom | BigQuery / Snowflake | Looker / Grafana | Webhook + seuil coût | Moyenne | Agents IA internes critiques mais non régulés |
| Entreprise structurée | 500k–5M requêtes/mois | Gouvernance & fiabilité | OpenTelemetry complet | Datadog LLM ou Arize AI | Snowflake / BigQuery | Grafana / PowerBI | SIEM + escalade | Élevée | Usage multi-BU, impact métier fort |
| Groupe / secteur sensible | > 5M requêtes/mois | Conformité & auditabilité | OpenTelemetry + tracing RAG | Arize AI + SIEM | Snowflake / Warehouse interne | BI interne | Supervision 24/7 | Très élevée | AI Act, exigences audit, données sensibles |
| Équipe R&D IA | Variable | Benchmark & expérimentation | Tracking prompts & modèles | Weights & Biases / LangSmith | Warehouse secondaire | Dashboard expérimentation | Non prioritaire | Moyenne | Comparaison modèles, fine-tuning |
| Approche Open Source / Souveraine | Variable | Contrôle total & hébergement interne | OpenTelemetry + logs JSON | Prometheus + Loki + Tempo | PostgreSQL / ClickHouse | Grafana | Alertmanager | Élevée | Secteur public, défense, santé |
Ce que chaque stack couvre réellement
| Dimension | Startup | PME structurée | Enterprise | Open Source |
|---|---|---|---|---|
| Latence & erreurs | ✔ | ✔ | ✔✔ | ✔✔ |
| Coût tokens | ✔✔ | ✔✔ | ✔✔ | ✔ |
| Qualité sémantique | Basique | Intermédiaire | Avancée (drift & scoring) | Custom |
| ROI métier | Simple | Structuré | Multi-entités | Custom |
| Conformité AI Act | Faible | Partielle | Structurée | Forte si bien conçue |
| Scalabilité | Bonne | Bonne | Très forte | Dépend équipe |
✔✔ = fortement structuré
9. Architecture hybride recommandée (quel que soit le profil)
| Couche | Rôle | Outils typiques |
|---|---|---|
| Instrumentation | Capturer tokens, latence, prompts, réponses | OpenTelemetry, logs JSON |
| Centralisation | Historisation & analyse | BigQuery, Snowflake |
| Évaluation qualité | Scoring hallucination & dérive | LLM-as-a-judge, Arize |
| Dashboard | Visualisation métier & technique | Looker, Grafana |
| Alerting | Détection anomalies temps réel | Slack, SIEM, Webhook |
10. Gouvernance, RGPD et AI Act
Surveiller les prompts implique :
- Pseudonymisation
- Politique de rétention
- Gestion des accès
- Journalisation
Avec l’AI Act européen, la traçabilité des décisions IA devient structurante. Une IA non traçable sera juridiquement fragile.
Contacter un expert IA
Vous déployez un chatbot, un agent métier ou un workflow intelligent ?
Nous auditons, instrumentons et structurons votre monitoring LLM pour une IA fiable, maîtrisée et rentable.
Parce qu’une IA non monitorée n’est pas une stratégie.
C’est un pari.